SmartEdit: Exploring Complex Instruction-based Image Editing with Multimodal Large Language Models
CVPR-2024 Highlight
Yuzhou Huang1,2*
Liangbin Xie2,3,5*
Xintao Wang2,4✉
Ziyang Yuan2,7
Xiaodong Cun4
Yixiao Ge2,4
Jiantao Zhou3
Chao Dong5,6
Rui Huang1
Ruimao Zhang1✉
Ying Shan2,4
1The Chinese University of Hong Kong, Shenzhen (CUHK-SZ)
2ARC Lab, Tencent PCG
3University of Macau
4Tencent AI Lab
5Shenzhen Institute of Advanced Technology
6Shanghai Artificial Intelligence Laboratory
7Tsinghua University
* Equal Contribution
✉ Corresponding Authors
SmartEdit aims at handling complex understanding (the instructions that contain various object attributes like
location, relative size, color, and in or outside the mirror) and reasoning scenarios.

[Paper]
[Code]
[BibTeX]
Abstract
Current instruction-based editing methods, such as InstructPix2Pix, often fail to produce satisfactory results in complex scenarios due to their dependence on the simple CLIP text encoder in diffusion models.
To rectify this, this paper introduces SmartEdit, a novel approach to instruction-based image editing that leverages Large Language Models (LLMs) with visual inputs to enhance their understanding and reasoning capabilities.
However, direct integration of these elements still faces challenges in situations requiring complex reasoning.
To mitigate this, we propose a Bidirectional Interaction Module that enables comprehensive bidirectional information interactions between the input image and the MLLM output.
During training, we initially incorporate perception data to boost the perception and understanding capabilities of diffusion models. Subsequently, we demonstrate that a small amount of complex instruction editing data can effectively stimulate SmartEdit's editing capabilities for more complex instructions.
We further construct a new evaluation dataset, Reason-Edit, specifically tailored for complex instruction-based image editing.
Both quantitative and qualitative results on this evaluation dataset indicate that our SmartEdit surpasses previous methods, paving the way for the practical application of complex instruction-based image editing.
SmartEdit Framework
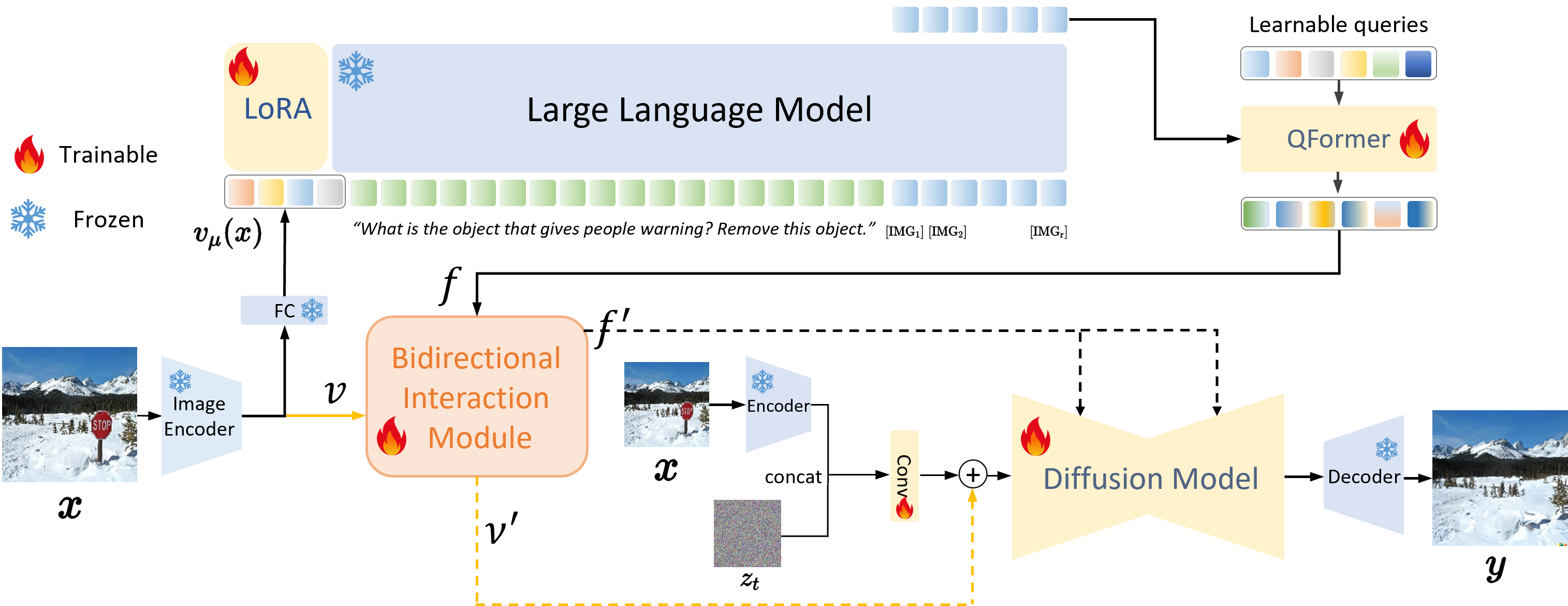
The overall framework of SmartEdit.
SmartEdit on Understanding Scenarios

Visual effects of SmartEdit on complex understanding scenarios.
It can be seen that for complex understanding scenarios,
SmartEdit has good instruction-based editing effects.
SmartEdit on Reasoning Scenarios

Visual effects of SmartEdit on complex reasoning scenarios.
It can be seen that for complex reasoning scenarios,
SmartEdit has good instruction-based editing effects.
SmartEdit on MagicBrush TestSet

The performance of SmartEdit on the MagicBrush test dataset.
SmartEdit has good editing effects on the MagicBrush test dataset,
not only for single-turn but also for multi-turn.
Comparisons on Understanding Scenarios

Qualitative comparison on complex understanding scenarios.
Compared to other methods,
SmartEdit can precisely edit specific objects in images according to instructions,
while keeping the content in other areas unchanged.
Comparisons on Reasoning Scenarios

Qualitative comparison on reasoning scenarios.
For reasoning scenarios,
SmartEdit can effectively utilize the reasoning capabilities of the LLM to identify the corresponding objects,
and then edit the objects according to the instructions.
Other methods perform poorly in these scenarios.
Comparisons on MagicBrush TestSet

Qualitative comparison between our SmartEdit, MagicBrush-168, MagicBrush-52, InstructDiffusion, and InstructPix2Pix.
Compared against other methods, SmartEdit effectively adheres to the instructions, showcasing superior results.
Our project page is borrowed from DreamBooth.